

As long as we find a webpage where having data of interest, we sometimes want to extract them automatically but don’t know how to do quickly. Thank to the lxml library, this work is performed quickly on the HTML document saved from the website. In this post, we are working together to understand what the lxml is and how it helps us do such tasks.
Table of Contents
A short introduction to Web Scraping
From Wikipedia, we would keep the original paragraphs on web scraping as below to ease understanding.
Web scraping, web harvesting, or web data extraction is data scraping used for extracting data from websites. The web scraping software may access the World Wide Web directly using the Hypertext Transfer Protocol or through a web browser. While web scraping can be done manually by a software user, the term typically refers to automated processes implemented using a bot or web crawler. It is a form of copying, in which specific data is gathered and copied from the web, typically into a central local database or spreadsheet, for later retrieval or analysis.
Web scraping a web page involves fetching it and extracting from it. Fetching is the downloading of a page (which a browser does when a user views a page). Therefore, web crawling is the main component of web scraping, to fetch pages for later processing. Once fetched, then extraction can take place. The content of a page may be parsed, searched, reformatted, its data copied into a spreadsheet, and so on. Web scrapers typically take something out of a page, to make use of it for another purpose somewhere else. An example would be to find and copy names and phone numbers, or companies and their URLs, to a list (contact scraping).
Web scraping is used for contact scraping, and as a component of applications used for web indexing, web mining and data mining, online price change monitoring and price comparison, product review scraping (to watch the competition), gathering real estate listings, weather data monitoring, website change detection, research, tracking online presence and reputation, web mashup and, web data integration.
Web pages are built using text-based mark-up languages (HTML and XHTML), and frequently contain a wealth of useful data in text form. However, most web pages are designed for human end-users and not for ease of automated use. As a result, specialized tools and software have been developed to facilitate the scraping of web pages.
Newer forms of web scraping involve listening to data feeds from web servers. For example, JSON is commonly used as a transport storage mechanism between the client and the webserver.
There are methods that some websites use to prevent web scraping, such as detecting and disallowing bots from crawling (viewing) their pages. In response, there are web scraping systems that rely on using techniques in DOM parsing, computer vision and natural language processing to simulate human browsing to enable gathering web page content for offline parsing.
Getting started with lxml tool
Python can be used to write a web page crawler to download web pages. But the web page content is massive and not clear for us to use, we need to filter out the useful data that we need. This article will tell you how to parse the downloaded web page content and filter out the information you need to use Python lxml library’s XPath method.
When it comes to string content filtering, we immediately think about regular expressions, but we won’t talk about regular expressions today. regular expressions are too complex for a crawler that is written by a novice. Moreover, the error tolerance of regular expressions is poor, so if the web page changes slightly, the matching expression will have to be rewritten.
The lxml XML toolkit is a Pythonic binding for the C libraries libxml2 and libxslt. It is unique in that it combines the speed and XML feature completeness of these libraries with the simplicity of a native Python API, mostly compatible but superior to the well-known ElementTree API. The latest release works with all CPython versions from 2.7 to 3.8. See the introduction for more information about the background and goals of the lxml project. Some common questions are answered in the FAQ.
Installation
We recommend you create a virtual Python environment and use the pip command to install the library.
pip install lxml
We can specify the version when installing the library as well. At the time of writing, the version is 3.4.2 as the latest release.
pip install lxml==3.4.2
Usage
Once the library is installed in your Python environment, there are many ways to import methods coming alongside lxml. For examples:
from lxml.html.soupparser import fromstring from lxml.etree import tostring import lxml.html import lxml.html.soupparser
Creating HTML Elements
With lxml, we can create HTML elements quickly. The elements can be also called as Nodes in line with the concepts of XPath. Let’s try to create a basic structure of an HTML document using this library. Below is sample code.
root_elem = etree.Element('html')
etree.SubElement(root_elem, 'head')
etree.SubElement(root_elem, 'title')
etree.SubElement(root_elem, 'body')
print(etree.tostring(root_elem, pretty_print=True).decode("utf-8"))
The output of the snippet above looks like
<html> <head/> <title/> <body/> </html>
The result reveals HTML elements being created via the SubElement method of the etree object. The pretty_print parameter is set True to print the output in a nice form of HTML document.
Each element is a Node in the entire tree, therefore, we can iterate over all elements normally. The data structure of a Node is a list which allows us to manipulate each element via a loop. Certainly, using the index operator to retrieve a specific element is completely doable.
# get the first tag/element from the root node html = root_elem[0] print(html.tag) for e in root_elem: print(e.tag)
Serialising a raw XML document
With feeding a raw XML data directly to XML method of etree object, we can create an HTML version of that data as we did manually create individual HTML elements in the earlier example.
from lxml import etree
html_text = '''
<!DOCTYPE html>
<html>
<head>
<title>Page Title</title>
</head>
<body>
<h1>This is a Heading</h1>
<p>This is a paragraph.</p>
</body>
</html>
'''
html = etree.XML(html_text)
print(etree.tostring(html, pretty_print=True).decode('utf-8'))
The output looks exactly similar to the HTML text.
To learn more about developing with lxml, I recommend visiting their website https://lxml.de/tutorial.html to familiarise yourself with the library.
Demo project
Disclaimer: This project aims to illustrate how to use lxml to parse HTML pages. We won’t recommend you to hack the content of certain pages or try to scrap them steadily if they do not permit to scrap automatically.
Description
In this project, we are going to extract the links of the 1920×1200 sized images from the webpage Audi A4 2016. Notes: this is the first page of the search results from the keywords “Audi A4 2016“. Due to the simplicity of the demo project, we don’t explain how to paginate to get all pages.
Step 1: Read and download the HTML content of this page
In this step, we are using the requests module to download the content of the entire page. The snippet below does what we need.
import requests
url = "https://all-free-download.com/wallpapers/audi-a4-2016.html"
headers = {'Content-Type': 'text/html', }
response = requests.get(url, headers=headers)
html_doc = response.content
The get method of the requests object will scrap the HTML page with the given options defined in the headers argument. The method returns a response object which we can retrieve some properties and access methods (see https://www.w3schools.com/python/ref_requests_response.asp). To get the content of the page, use the content property.
Step 2: Apply lxml to parse the HTML segment
In this step, using the HTML method of the etree package to parse the HTML content.
from lxml import etree
from lxml.etree import ParserError
try:
parser = etree.HTMLParser()
html_dom = etree.HTML(html_doc, parser)
except ParserError as e:
print(e)
There are some methods to parse HTML documents, however, we use etree.HTML because it returns an HTML DOM object to be useful in the next step. It won’t work if we use html_dom = etree.parse(StringIO(html_doc), parser). The etree.HTML needs two required arguments. The first is the HTML document while the second is HTMLParser object.
Step 3: Extract links
This step mainly employes the xpath method on the HTML DOM object parsed from the previous step. Let’s have a look at the first page of search results.
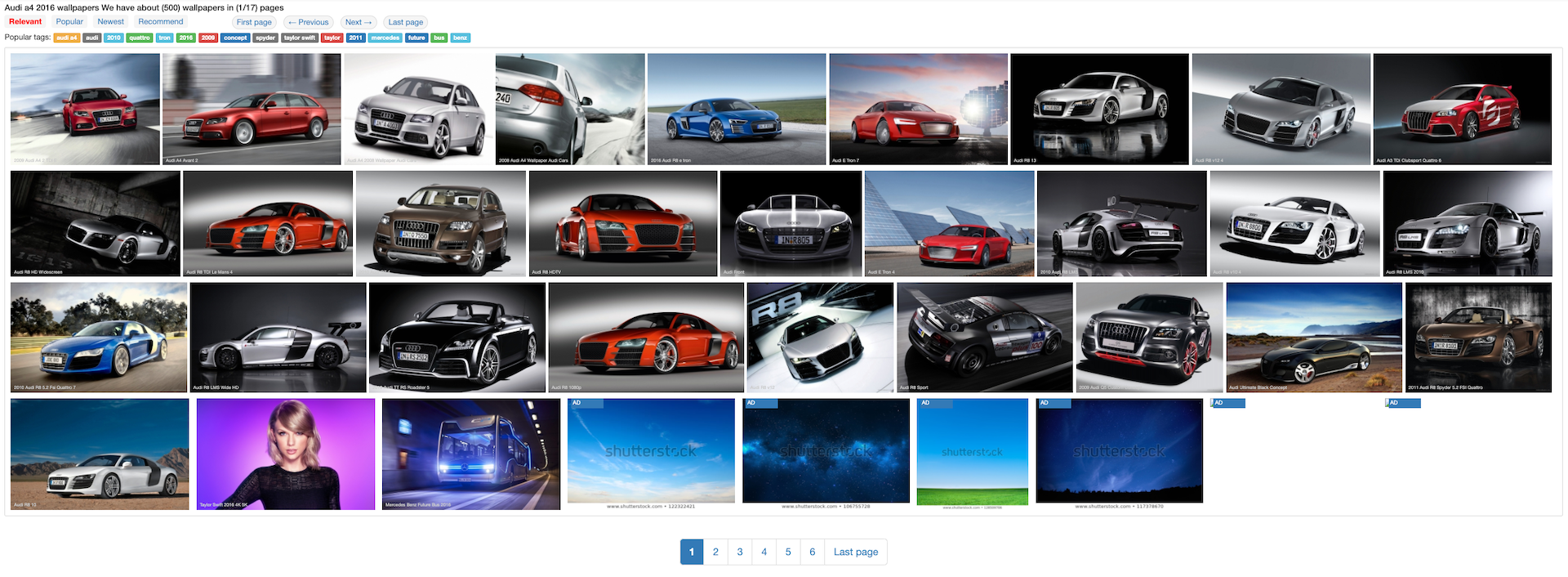
All thumbnails are put in a div called imgcontainer. Each thumbnail lies in another div coming along the class named item. However, you can see some irrelevant images where some advertisements are being adhered. Therefore, we restrict them from selecting. The XPath sequence looks like.
urls = html_dom.xpath('//div[@class="imgcontainer"]/div[@class="item"]/a[contains(@href, "download") and contains(@href, "audi")]/@href')
When clicking on each image in this page, it will take you to another page where that image is shown on the top and other similar images are displayed underneath like the screenshot below.

Let’s analyse the HTML code of the image link.
<td><a href="http://files.all-free-download.com//downloadfiles/wallpapers/1920_1200/audi_a4_avant_2_5059.jpg" title="Audi A4 Avant 2"><i style="color:green;" class="glyphicon glyphicon-ok"></i> 1920_1200</a></td>
The link has 1920_1200 as the image size and contains audi_A4 as the keywords. However, there are many other links we don’t want to grab. Therefore, we have to combine some criteria. After thinking carefully, XPath is defined.
urls = html_dom.xpath('//a[contains(@href, "wallpapers/1920_1200")]/@href')
The entire snippets are grouped as below.
from lxml.etree import ParserError
from lxml import etree
import requests
def parse_html_doc(_html_doc):
_html_dom = None
try:
_parser = etree.HTMLParser()
# html_dom = etree.parse(StringIO(html_doc), parser)
_html_dom = etree.HTML(_html_doc, _parser)
except ParserError as e:
print(e)
return _html_dom
url = "https://all-free-download.com/wallpapers/audi-a4-2016.html"
headers = {'Content-Type': 'text/html', }
response = requests.get(url, headers=headers)
html_doc = response.content
html_dom = parse_html_doc(html_doc)
urls = html_dom.xpath(
'//div[@class="imgcontainer"]/div[@class="item"]/a[contains(@href, "download") and contains(@href, "audi")]/@href')
print(len(urls))
if urls:
for e in urls:
print(e)
response = requests.get(e, headers=headers)
html_dom = parse_html_doc(response.content)
urls = html_dom.xpath('//a[contains(@href, "wallpapers/1920_1200")]/@href')
if len(urls):
print(urls[0])
I posted an article about downloading files using wget or urllib module. From the links of wallpaper images, you entirely know how to download them from their URLs.
Source code
If you’re interested in our article and want to figure out more, the public source code can be found here add5d5f.
Conclusion
Fortunately, Python provides many libraries for parsing HTML pages such as Bs4 BeautifulSoup and Etree in LXML (an XPath parser library). BeautifulSoup looks like a jQuery selector, it looks for HTML elements through the id, CSS selector, and tag. Etree’s Xpath method looks for elements primarily through nested relationships of HTML nodes, similar to the path of a file. Below is an example of using Xpath to find HTML nodes.
In the above tutorial, we started with a basic introduction to what lxml library is and what it is used for. After that, we learned how to install it on different environments like Windows, Linux, etc. Moving on, we explored different functionalities that could help us in traversing through the HTML/XML tree vertically as well as sideways. In the end, we also discussed ways to find elements in our tree, and as well as obtain information from them.
We hope you find this post interesting and useful for your project. If you have any comment, don’t hesitate to leave your message in the box below.
Please consider financially supporting us!