

Machine learning algorithms are described as either ‘supervised’ or ‘unsupervised’. The distinction is drawn from how the learner classifies data. In supervised algorithms, the classes are predetermined. These classes can be conceived of as a finite set, previously arrived at by a human. In practice, a certain segment of data will be labelled with these classifications. The machine learner’s task is to search for patterns and construct mathematical models. These models then are evaluated on the basis of their predictive capacity in relation to measures of variance in the data itself. Many of the methods referenced in the documentation (decision tree induction, naive Bayes, etc) are examples of supervised learning techniques.
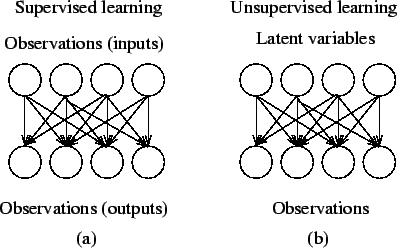
Unsupervised learners are not provided with classifications. In fact, the basic task of unsupervised learning is to develop classification labels automatically. Unsupervised algorithms seek out similarity between pieces of data in order to determine whether they can be characterized as forming a group. These groups are termed clusters, and there are a whole family of clustering machine learning techniques.
In unsupervised classification, often known as ‘cluster analysis’ the machine is not told how the texts are grouped. Its task is to arrive at some grouping of the data. In a very common of cluster analysis (K-means), the machine is told in advance how many clusters it should form — a potentially difficult and arbitrary decision to make.
It is apparent from this minimal account that the machine has much less to go on in unsupervised classification. It has to start somewhere, and its algorithms try in iterative ways to reach a stable configuration that makes sense. The results vary widely and may be completely off if the first steps are wrong. On the other hand, cluster analysis has a much greater potential for surprising you. And it has considerable corroborative power if its internal comparisons of low-level linguistic phenomena lead to groupings that make sense at a higher interpretative level or that you had suspected but deliberately withheld from the machine. Thus cluster analysis is a very promising tool for the exploration of relationships among many texts.
Source: http://monkpublic.library.illinois.edu/monkmiddleware/public/analytics/clusterclassification.html
———–
Các thuật toán máy học thường được mô tả dưới dạng là ‘giám sát’ hoặc ‘không giám sát’. Sự phân biệt này được vạch ra khi từ lúc người học phân lớp dữ liệu. Trong những thuật toán giám sát, các lớp cần được xác định trước từ ban đầu. Những lớp này được hiểu là hữu hạn, và được đưa ra trước đó do người dùng tự xác định. Trong thực tế, việc phân lớp này sẽ được đặt tên thông qua công việc phân đoạn dữ liệu nào đó. Nhiệm vụ của chương trình học máy là tìm kiếm những mẫu dữ liệu và những mô hình toán học xây dựng. Những mô hình sau đó được đánh giá dựa trên cơ sở khả năng tiên đoán của chúng trong mối quan hệ với các phép đo biến đổi trên chính dữ liệu đó. Nhiều phương pháp tham khảo trong bài viết này (cây quyết định quy nạp, naive Bayes, etc) là những ví dụ về kỹ thuật học máy giám sát.